Nurix’s Dialogue Manager listens to both sides of the conversation, capturing acoustic and semantic cues in real time, to ensure voice bots respond naturally and know when to speak, pause, or listen.
Nurix Dialogue Manager
Smarter Turn-Taking for Voice AI

Why Dialogue Management is Crucial for Voice AI?
Voice AI often fails at one of the most basic human skills: knowing when to talk and when to listen. Without intelligent dialogue management, voice assistants talk over users, pause awkwardly, or misinterpret simple affirmations like “mhmm” as interruptions.
This results in broken, robotic experiences, especially in real-time applications like customer support, smart assistants, or in-car systems.
Voice AI’s Conversational Blind Spot
Despite advances in speech recognition and large language models, most voice AI systems still fail at one crucial skill: managing the flow of conversation. They don’t truly listen. They rely on rigid rules or silence thresholds to decide when to speak, often leading to interruptions, awkward pauses, or missed cues.These systems can’t handle subtle conversational signals like a quick “uh-huh” or a hesitant pause which humans instinctively understand.
The Result?
Voice assistants that feel clunky, robotic, and frustrating in live interactions.
Traditional Voice Pipelines Fall Short
Most voice AI architectures rely on a three-part stack:
Speech-to-Text (STT/ASR)
Converts audio streams to text transcripts. Modern streaming STT engines achieve ~90ms latency, but formatting processes (punctuation, capitalization, number normalization) can add significant overhead.
Large Language Model (LLM) Response Generator
Processes transcribed text and generates textual responses. High-performance inference engines can achieve ~200ms processing time, but token generation is inherently sequential and latency-sensitive to prompt length and max tokens.
Text-to-Speech (TTS) Synthesis
Converts LLM output to audio streams. Low-latency TTS engines achieve ~75ms time-to-first-byte with streaming optimization, but voice quality and latency remain inversely correlated.
The Voice-to-Voice Alternative
The industry is also moving toward Voice-to-Voice (V2V) models that bypass text entirely, processing audio input directly to audio output. These models offer:
Ultra-low Latency
Direct audio-to-audio processing eliminates transcription delays.
Preserved Vocal Nuances
Tone, emotion, and acoustic context remain intact.
Natural Conversational Flow
No text bottleneck disrupting speech rhythm.
The Dialogue Management Problem
For turn detection and conversation orchestration, current systems predominantly rely on Voice Activity Detection (VAD) combined with rule-based logic to determine speaking turns.
Traditional VAD approaches struggle with:
Fixed Silence Thresholds:
Default settings often include Wait Seconds: 0.4s, On PunctuationSeconds: 0.1s, On No Punctuation Seconds: 1.5s, which can add 1500ms to optimized 365ms pipelines.
Acoustic-only Processing:
No semantic understanding of utterance completeness.
Binary Speech/Non-Speech Classification:
Cannot distinguish between pause types (hesitation vs. completion).
Backchannel Misinterpretation:
Treats supportive utterances ("mhmm", "uh-huh") as interruptions.
Context-agnostic Decisions:
Ignores conversational state and speaker intent.
Meet Nurix's Dialogue Manager
Nurix's Dialogue Manager brings a new level of intelligence to voice conversations by analyzing real-time audio from both the user and the AI, not just one side. Instead of depending on fixed silence gaps or overlap thresholds, it listens like a human would, using semantic understanding and acoustic cues to determine when to speak, pause, or continue.
This allows your voice assistant to respond faster, sound more natural, and adapt instantly to interruptions, pauses, and subtle affirmations, even in messy or fast-paced conversations.
Key Differentiators
Simultaneous Audio Processing
From both speaker and listener.
Real-time Detection
Of tone, intent, and conversational flow.
Proprietary Turn-taking Algorithms
That go beyond silence-based rules.
No Reliance on Rigid Silence-based Rules
Architecture-agnostic Design
Works with both traditional pipelines and V2V models.
What Nurix Dialogue Manager Enables
Accurate Turn-End Detection
Knows when the user is done speaking.
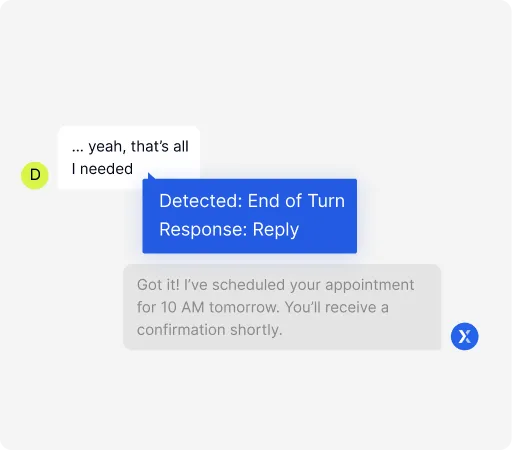
Real-Time Interruption Handling
Immediately pauses if a user interjects.

Backchannel Support
Recognizes "mhmm", "yeah", "uh-huh" and keeps speaking.

Lower Latency
No need to wait for arbitrary silence.
Contextual Intelligence
Reacts based on full conversation state, not just audio gaps.
These capabilities ensure smoother, smarter conversations across all voice-first applications.
Real-World Impact for Voice Applications
With Nurix Dialogue Manager, your voice assistant can listen, understand, and respond like a human; even in fast-paced, noisy, or emotionally complex conversations.
Customer support bots that never talk over customers.
Virtual assistants that handle natural interruptions smoothly.
In-car or smart device voice control with real-time reactivity.
Accessibility tools that adjust to varied speech patterns.

Future of Enterprise AI

